There’s a narrative that AI-assisted coding produces sloppy, unmaintainable “vibe code.” Prompt in, code out, ship it, pray.
I’d like to push back on that.
TalkKeys is a voice-to-text desktop app I built mostly with AI assistance. It’s also properly architected, testable, and running in production via the Windows Store. These things aren’t contradictory.
What AI Actually Accelerated
Let me be clear about what AI helped with and what it didn’t.
AI accelerated: boilerplate, API research, drafting implementations, catching mistakes faster than a compiler.
AI didn’t decide: architecture, abstractions, error handling patterns, interface contracts.
The architecture decisions were mine. The speed of implementation was AI-assisted. That distinction matters.
The Stack
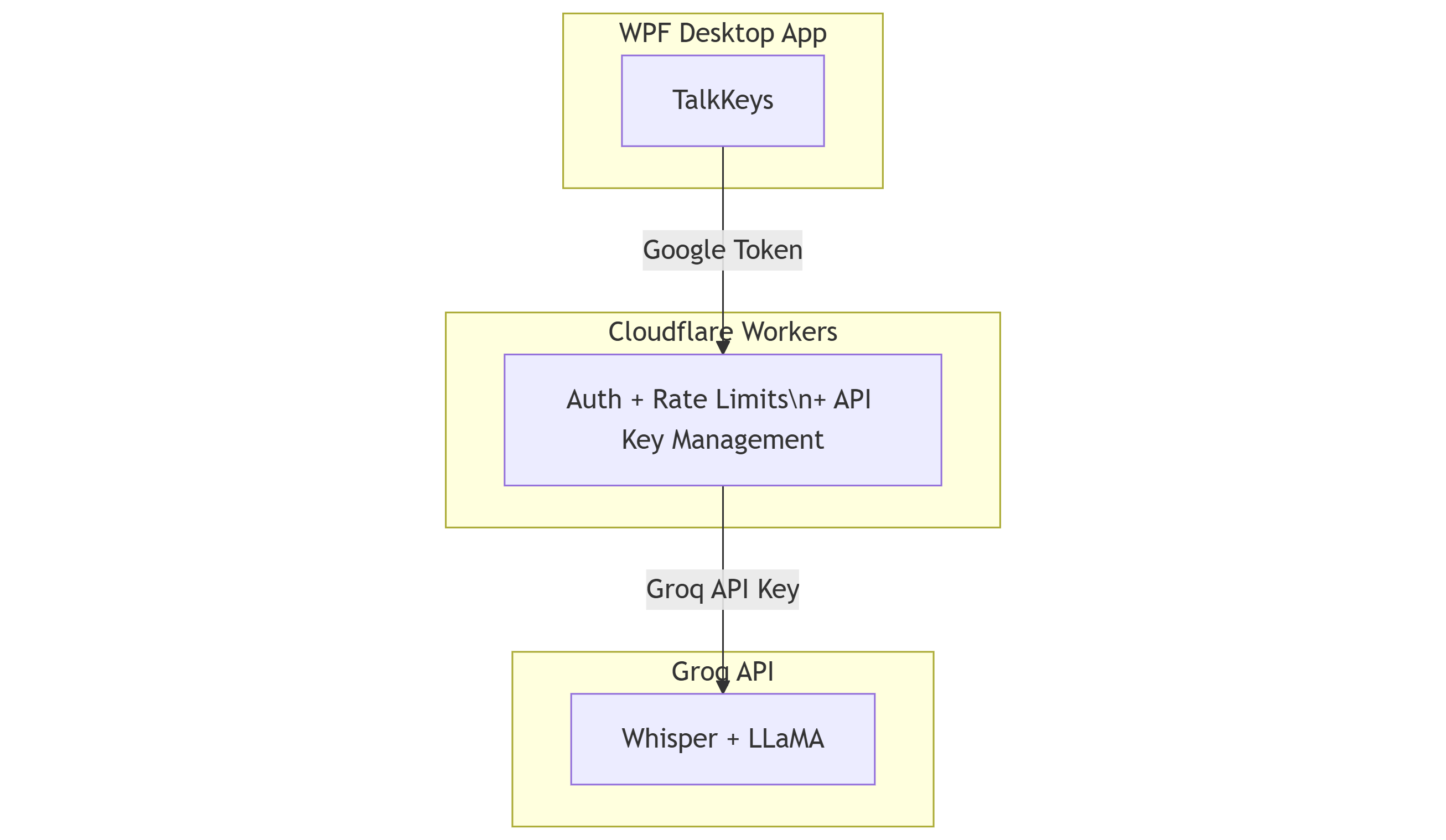
Three layers. Each with a clear job.
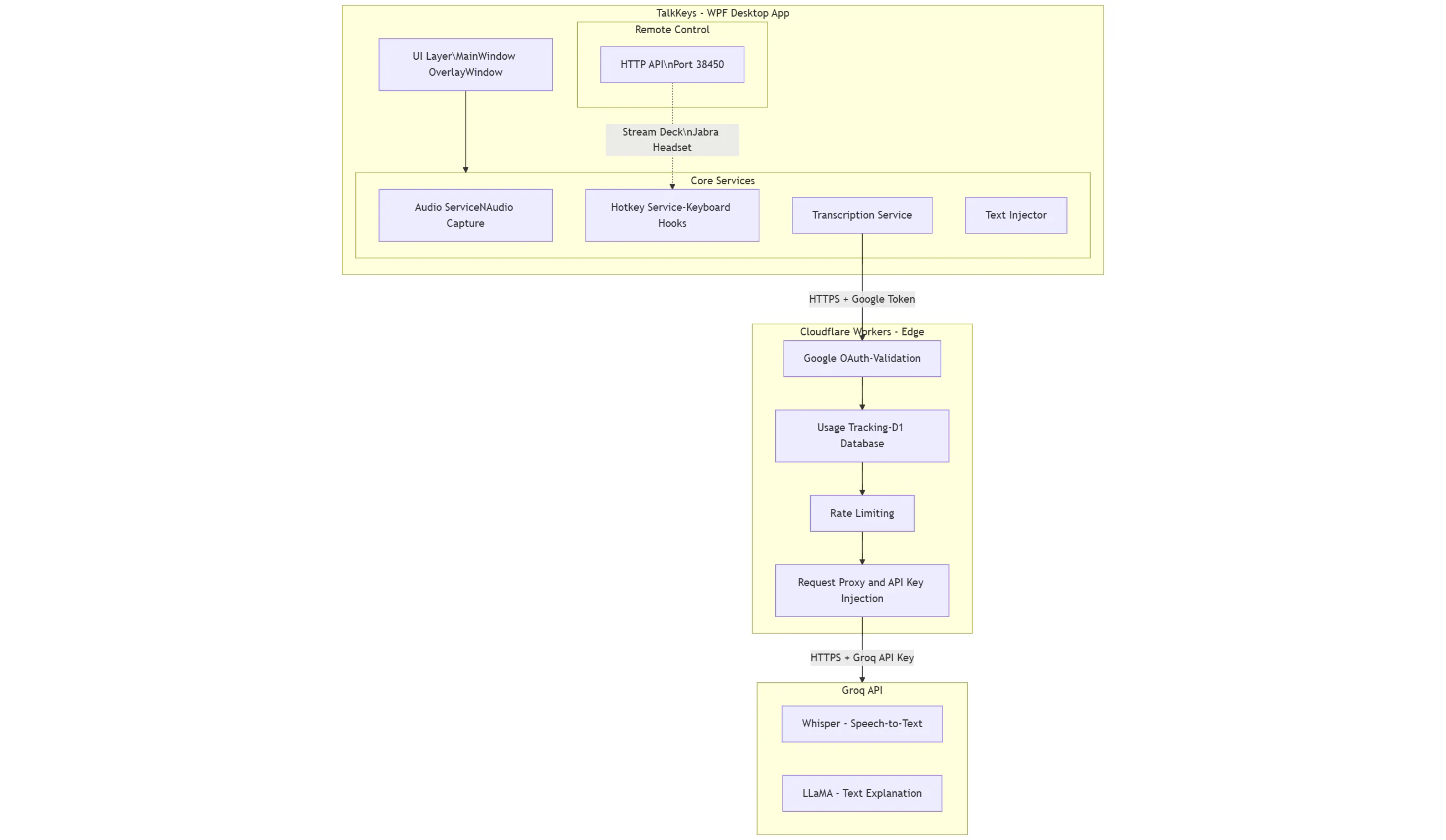
Layer 1: WPF Desktop Application
The client handles everything local: audio capture, keyboard hooks, text injection, UI.
Clean Architecture with clear interfaces for each capability. Each service does one thing. Each interface describes a contract, not an implementation. Every service gets injected at startup. This sounds academic until you need to test something. Want to test transcription without calling Groq? Inject a mock. Want to verify hotkey handling without capturing the actual keyboard? Mock it. The interfaces make this trivial. When I switched audio libraries mid-development, I changed one class. Everything else kept working.
The local HTTP API on port 38450 turned out to be perfect for integration testing. Originally built so I could trigger transcription from my Jabra headset, I can now spin up the app and hit endpoints programmatically to verify the full flow. No flaky UI automation. Just HTTP calls against a running instance.
Layer 2: Cloudflare Workers
This is the bit that makes “AI calls on me” possible without going bankrupt.
The desktop app never talks to Groq directly. Every request goes through Cloudflare Workers, which validates Google tokens, tracks usage in D1, enforces daily limits, and injects my Groq API key server-side.
Users never see my credentials. I never get surprise bills. If I need to rotate the API key or change providers, I update the Worker. No app update required.
Layer 3: Groq API
Groq runs Whisper for transcription and LLaMA for the WTF explanations. It’s fast - noticeably faster than other providers I tried.
The desktop app doesn’t know Groq exists. It calls my Cloudflare endpoint. Swap providers tomorrow, client stays the same.
The Point
This is a personal project, but it’s architected like a real product. Not because I expect enterprise adoption, but because proper architecture costs almost nothing upfront and saves pain later.
AI helped me build this faster. The decisions about layers, interfaces, and security boundaries were human decisions, informed by years of shipping software.
That’s not vibe coding. That’s using tools effectively.